Python 如何使用 BeautifulSoup 实现解析二手房详情页信息并存储文件
发表于 : 2023年 1月 12日 17:43
一、实战场景
Python 如何使用 BeautifulSoup 实现解析二手房详情页信息并存储文件
二、知识点
Python 基础语法
Python 文件读写
BeautifulSoup 解析网页
requests 发送网络请求
三、菜鸟实战
详情页数据采集
存储采集数据到文件
运行结果
运行截图
采集详情页运行截图
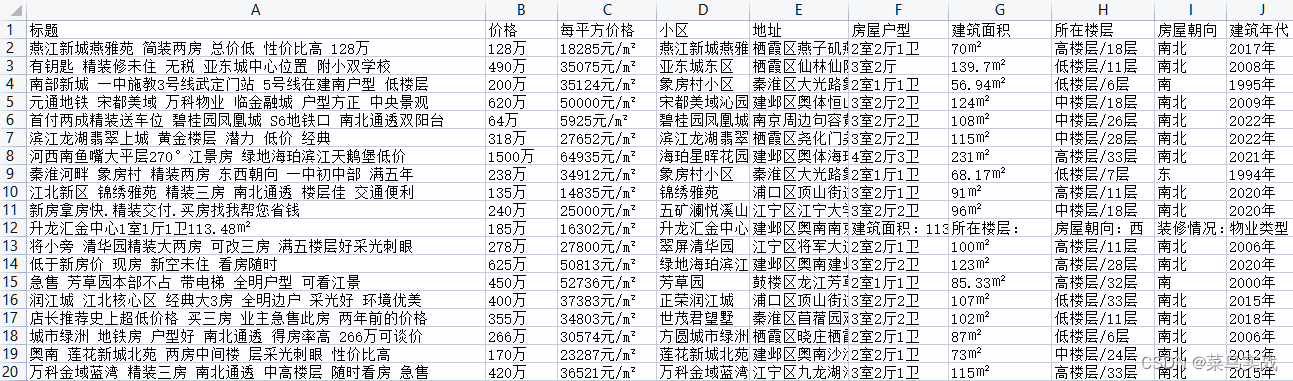
结果文件
菜鸟实战,持续学习!
Python 如何使用 BeautifulSoup 实现解析二手房详情页信息并存储文件
二、知识点
Python 基础语法
Python 文件读写
BeautifulSoup 解析网页
requests 发送网络请求
三、菜鸟实战
详情页数据采集
代码: 全选
import os.path
import platform
from base_spider import BaseSpider
from bs4 import BeautifulSoup
import pandas as pd
from tqdm import tqdm # 进度条库
class Tao365DetailSpider(BaseSpider):
# 采集365淘房二手房信息
list_data_file = 'tao365_list.csv' # 采集数据保存的文件
detail_data_file = 'tao365_detail.csv' # 采集数据保存的文件
url_items = [] # 采集链接数组, 取自列表文件中的每一行
detail_df = [] # 已采集的信息
def __init__(self):
# 初始化日志
self.init_log()
# 从列表文件读取等待采集的链接
list_file_path = self.fileManger.get_data_file_path(self.list_data_file)
list_df = pd.read_csv(list_file_path, encoding=self.encoding)
self.url_items = list_df.values # 初始化待采集链接数组
detail_file_path = self.fileManger.get_data_file_path(self.detail_data_file)
if os.path.isfile(detail_file_path):
# 从详情文件读取已采集的信息
self.data_file_exist = True
detail_df = pd.read_csv(detail_file_path, encoding=self.encoding)
self.detail_df = detail_df
def check_url_crawled(self, url):
# 检查当前链接是否被抓取过
if len(self.detail_df) == 0:
# 如果没有详情文件,则未抓取
return False
if url in self.detail_df.iloc[:, 1].values:
# 如果 url 在详情文件第一列中有,则表示已抓取过
self.logger.warning("url 已抓取过 %s", url)
return True
# 默认为未抓取
return False
def parse_page(self, content, url):
# 利用BeautifulSoup标准库,解析页面信息
soup = BeautifulSoup(content, 'lxml')
# 初始化数组
datalist = []
if soup.find("p", attrs={'class': 'line1'}):
# 标题
title = soup.find("p", attrs={'class': 'line1'}).text
# 价格
priceSplit = soup.find('span', attrs={'class': 'f48 pre bold'}).text.strip()
priceArr = priceSplit.split(' ')
price = priceArr[0] + "万"
# 每平方价格
squarePrice = soup.find('div', class_='headinfo').find('p').text.strip()
# 小区
housing = soup.find('div', attrs={'class': 'infoDetail__item long'}).find('a', class_='line1').text
area = soup.find('div', attrs={'class': 'infoDetail__item long line1'}).text
areaArr = area.split(' ')
# 地址
areaStr = ''
for area in areaArr:
area = area.replace('\n', '')
area = area.replace('地址:', '')
if area.replace('\n', '') != '地址:':
if len(area) > 0:
areaStr = areaStr + (area.replace('\n', ''))
ul = soup.find("ul", attrs={'class': 'detail__mainCotetn__infoBar'})
lis = ul.find_all("li")
# 房屋户型
house_type = lis[0].text.replace('房屋户型:', '').replace('\n', '').strip()
# 建筑面积
acreage = lis[1].text.replace('建筑面积:', '').replace('\n', '').strip()
# 所在楼层
level = lis[2].text.replace('所在楼层:', '').replace('楼层咨询', '').replace('\n', '').strip()
# 房屋朝向
direction = lis[3].text.replace('房屋朝向:', '').replace('\n', '').strip()
# 建筑年代
year = lis[5].text.replace('建筑年代:', '').replace('\n', '').strip()
datalist.append([title, price, squarePrice, housing, areaStr, house_type, acreage, level, direction, year])
return datalist
def crawl_data(self):
# 采集数据
for url_item in tqdm(self.url_items):
url = url_item[1]
if self.check_url_crawled(url):
continue
self.logger.debug("当前采集页面信息: %s", url)
# 发送请求, 获取数据
page_content = self.get_content_from_url(url)
# 解析数据
page_data = self.parse_page(page_content, url)
if len(page_data) == 0:
# 未获取到数据, 则继续分析下一个
continue
# 保存数据到文件
cols = ['标题', '价格', '每平方价格', '小区', '地址', '房屋户型', '建筑面积', '所在楼层', '房屋朝向', '建筑年代']
self.save_to_detail_file(page_data, cols)
# 防止反爬, 随机休眠一段时间
self.sleep_random()
def run(self):
self.logger.debug("采集开始")
self.crawl_data()
self.logger.debug("采集结束")
if __name__ == '__main__':
print("采集365淘房二手房信息详情")
spider = Tao365DetailSpider()
spider.run()
print("python 版本", platform.python_version())代码: 全选
def save_to_file(self, data, cols):
# 保存到文件
file_path = self.fileManger.get_data_file_path(self.list_data_file)
# 初始化数据
frame = pd.DataFrame(data)
if not self.data_file_exist:
# 第一次写入带上列表头,原文件清空
frame.columns = cols
frame.to_csv(file_path, encoding=self.encoding, index=None)
self.data_file_exist = True # 写入后更新数据文件状态
else:
# 后续不写如列表头,追加写入
frame.to_csv(file_path, mode="a", encoding=self.encoding, index=None, header=0)
self.logger.debug("文件保存完成")运行截图
采集详情页运行截图
采集365淘房二手房信息详情
100%|██████████| 222/222 [08:37<00:00, 2.33s/it]
python 版本 3.9.10
进程已结束,退出代码0
结果文件
菜鸟实战,持续学习!